摘要:为纪念抗日战争胜利70周年,基于CNKI数据库对抗战相关文献进行搜索并统计研究。应用基础统计学和ROSCM分析软件对抗战相关文献的搜索结果条目进行文本统计与挖掘。通过统计分析、词频分析和语义网络对高被引文献进行特征分析,表明抗战学术研究领域已产出一批具有高价值的成果,其仍是研究领域的热点。
关键词:抗战;高被引;统计;CNKI
1 引言
2015年是中国人民抗日战争胜利70周年,也是世界反法西斯战争胜利70周年。为缅怀革命先烈的丰功伟绩,弘扬中华民族精神,诸多学者对抗战进行了详细的历史、人文、人物和政策等多个方面的研究[1]。为了对抗战学术研究成果进行统计分析研究,文本基于CNKI数据库对抗战相关文献进行搜索并统计研究。
文中应用基础统计学方法和ROSTCM分析软件分别对抗战相关文献及高被引文献的搜索条目进行文本统计与挖掘[2]。对抗战相关文献发表数量进行简单的统计表述,对高被引文献分别进行统计概述、词频分析、语义网络分析等研究。
2 抗战文献概述
在中国知网CNKI中进行抗战相关文献搜索,其检索方法(表1)如下:
表1 检索方法

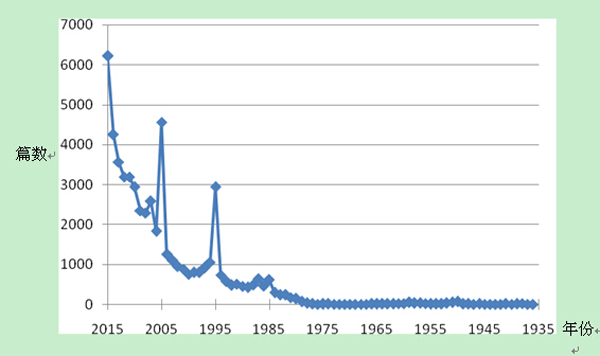
图1 抗战文献历年发表数量
经搜索后总计得到56149条文献结果,按照其发表年度分布如上(图1)。从图1中可以看出,1980年后文献发表数量趋于递增,表明这一领域的研究热度仍然保持活跃。特别是在三个峰值年份,依次为1995、2005和2015年,这也与抗战胜利50、60和70周年所相对应。
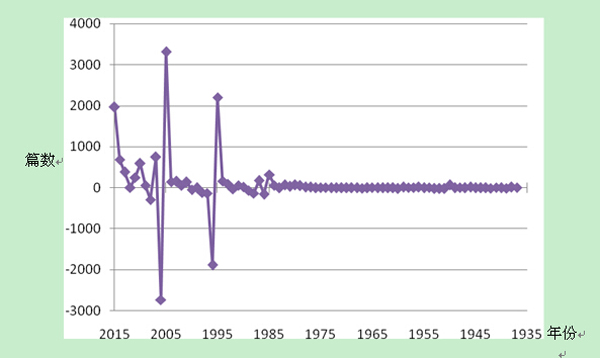
图2 发表文献增幅
从抗战文献的发表增幅(图2)可以看到,1935至1985年间发表数量平稳,而1985年后各年份文献发表数量产生较大波动,最高的三个峰值依次为2005、1995和2015年,这同样与与抗战胜利60、50和70周年相对应。从增幅图中可以到,最低的两个年份分别为2006和1996年,恰好是最高峰值的下一年。所以可以得到结论,每经历一个较高增长峰值的年份,下一年相关文献数量跌幅也是最大,即可以预测2016年抗战文献发表量将会锐减。
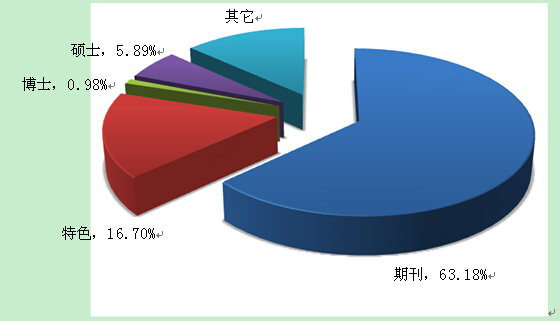
图3 来源数据库分布饼状图
根据来源数据库对抗战文献数量进行统计(图3):中国学术期刊网络出版总库(35477篇);特色期刊(9377篇);中国博士学位论文全文数据库(549篇);中国优秀硕士学位论文全文数据库(3308篇)。从图3中可以看到,期刊类文献的比重依然最大,而博硕论文也在发表文献数量中占有一定比例。
在其它分组发表文献数量的分布中,学科分布前三依次为:中国近现代史(20704篇);中国文学(6463篇);人物传记(5617篇)。层次研究分布前三:基础研究(社科)(30876篇);大众文化(5081篇);政策研究(社科)(4407篇)。机构分布前三:西南大学(503篇);华中师范大学(482篇);南京大学(423篇)。基金分布前三:国家社会科学基金(830篇);湖南省社会科学基金(62篇);中国博士后科学基金(54篇)。上述各分组分布中,仅有机构分布较为接近,表明这一领域的研究机构较为均衡,而其它分组的研究成果差距较大。
根据上述文献搜索的结果表明,抗战仍是我国社会科学研究领域的热点,特别是在近年产出大量的科研成果,表明其具有高的研究价值。而为了进一步体现出高水平文献的价值,对高被引文献进行统计分析。
3 高被引文献分析
论文引用率是指科学论文对文献的引用次数,体现论文的科学研究价值[3]。因此对高被引文献进行统计分析更能体现出研究领域的科研价值。
3.1 简要统计
对上述56149条文献搜索结果按照被引次数进行排序,选取被引次数≥10的文献导出分析,获得128篇高被引文献,其中期刊116篇(90.6%),硕士论文7篇(5.5%),博士论文5篇(3.9%)。128篇高被引文献的被引次数(图4)分布如下。其中最高被引次数达64次,128篇高被引文献的平均被引次数达17.5次,这一数据表明这批抗战文献具有较高的科研价值。
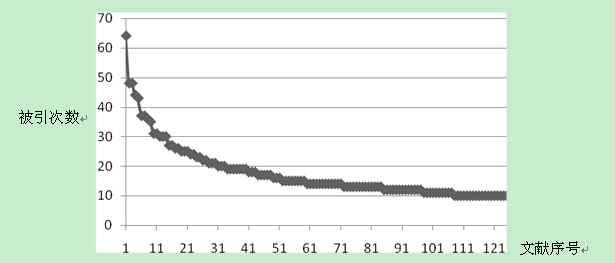
图4 被引次数
3.2 词频分析
TF(term frequency)词频,其常用于情报检索与文本挖掘技术,用以评估某个词对于一个文件或一个语料库中的某个领域集合的重要程度。随着词语在文件中出现的次数,它的重要性成正比增加。词频分析经常被各类搜索引擎所应用,作为文本与用户搜索查询关联程度的度量或评级[4]。因此,为了准确的评估这128高被引文献的文本特征,对其关键词进行词频统计(图5)。
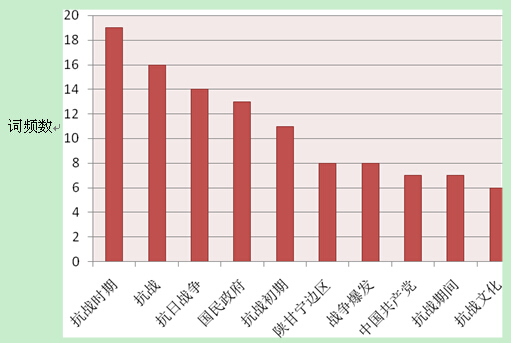
图5 关键词的词频分布
从图5中可以看到,高被引文献关键词出现频数最多的十个词分别是:“抗战时期”、“抗战”、“抗日战争”、“国民政府”、“抗战初期”、“陕甘宁边区”、“战争爆发”、“中国共产党”、“抗战期间”和“抗战文化”。其中“抗战时期”出现了19次,是高被引文献中出现最多的关键词。
上述仅罗列出频数最多的十个关键词,为了更好的展示词频分析,使用词云图对整个关键词频数进行表示(图6)。词云,即在视觉上突出文本中出现频数较高的关键词语吗,从而构成“关键词渲染”或是“关键词云层”。这在视觉效果上可以迅速过滤掉大量文本信息。使得阅读者可以快速领会文本的主要含义[5]。如图6所示,可以在关键词的词云图中迅速的看到上述频数最多的十个词语。

图6 关键词的词云图
3.3 语义网络分析
文本特征分析中一个重要的组成部分即是语义网络分析,它是一种采用网络形式表示人类知识的方法。在1968年,Quillian在其博士论文中提出语义网络分析,将其作为人类联想记忆的一个显式心理学模型。而在1972年,语义网络的概念被正式提出,并且应用于自然语言理解的研究。语义网络是一个带标示的有向图,结点之间带有标识的有向弧标识结点之间的语义联系,是语义网络组织的关键。其中这些结点可以表示问题领域中的物体、概念、时间或者动作等,一般划分为实例节点和类节点[6]。
本文中应用语义网络对高被引文献的标题进行分析,应用ROSTCM软件对128篇高被引的标题进行处理,得到语义网络关系图(图7)。从图中即可看出以“抗战”为核心的词语关联分布情况,围绕该核心分布的相关词语有“运动”、“中国”、“共产党”、“民众”、“国民政府”、“政策”、“美国”和“问题”等词语,即表示这些高被引文献的抗战研究方向。
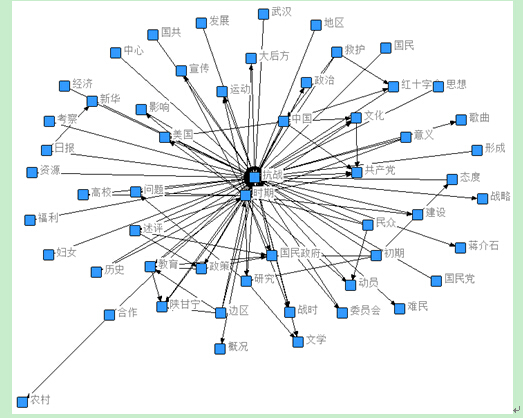
图7 语义网络关系图
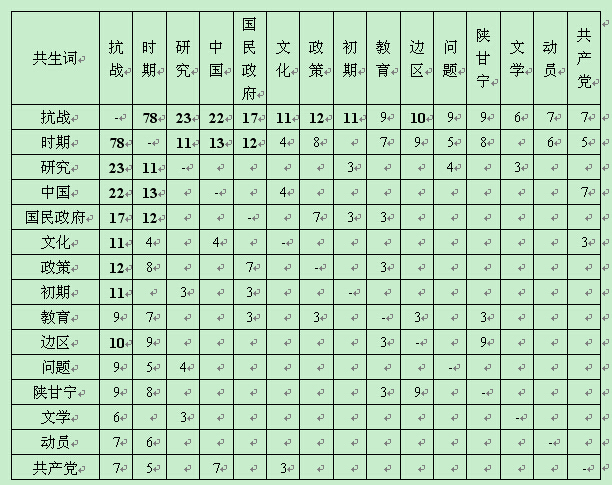
共生词是指在一段文本中,同时出现两个词语的情况,通过共生词出现次数的统计,可以得到其共生矩阵[7]。应用ROSTCM软件对128篇高被引的标题进行处理,得到共生矩阵(表1)。从共生矩阵中可以看到,出现频次最高的共生词有:“抗战——时期”、“抗战——研究”、“抗战——中国”、“抗战——国民政府”、“抗战——文化”、“抗战——政策”、“抗战——初期”、“抗战——边区”、“研究——时期”、“中国——时期”和“国民政府——时期”等。这些高频共生词也反映出与抗战研究相关的领域内容。
表1 共生矩阵
4 结论
文章基于CNKI数据库对抗战相关文献进行搜索并统计研究。应用基础统计学方法和ROSTCM分析软件分别对抗战相关文献及高被引文献的搜索条目进行文本统计与挖掘。对抗战相关文献发表数量进行简单的统计表述,对高被引文献分别进行统计概述、词频分析、语义网络分析等研究。
回首过往的70年,诸多学者为缅怀革命先烈的丰功伟绩,弘扬中华民族精神而进行大量抗战研究。结论表明抗战学术研究领域已产出一批具有高价值的成果,其仍是研究领域的热点,同时也激励后人不断进取,为谱写“中国梦”做出贡献。
参考文献
[1] 史桂芳. 一部史论与史料有机结合的抗战史研究力作——《中国抗日战争与第二次世界大战统计》评介[J]. 军事历史, 2012, 05: 76.
[2] 沈阳. ROST ContentMining System: software for Content Mining and Analysis. Wuhan University, 2008.
[3] 肖红, 袁飞, 邬建国. 论文引用率影响因素——中外生态学期刊比较[J]. 应用生态学报, 2009, 05: 1253-1262.
[4] 李文兰, 杨祖国. 中国情报学期刊论文关键词词频分析[J]. 情报科学, 2005, 01: 68-70+143.
[5] 唐家渝, 孙茂松. 新媒体中的词云: 内容简明表达的一种可视化形式[J]. 中国传媒科技, 2013, 11: 18-19.
[6] 李洁, 丁颖. 语义网、语义网格和语义网络[J]. 计算机与现代化, 2007, 07: 38-41.
[7] 杨霞, 黄陈英. 文本挖掘综述[J]. 科技信息, 2009, 33: 82+99.


